BioStructures documentation
The BioStructures.jl package provides functionality to manipulate macromolecular structures, and in particular to read and write Protein Data Bank (PDB), mmCIF and MMTF files. It is designed to be used for standard structural analysis tasks, as well as acting as a platform on which others can build to create more specific tools.
It compares favourably in terms of performance to other PDB parsers - see some benchmarks online and the benchmark suite. The PDB, mmCIF and MMTF parsers currently read in the whole PDB without explicit errors (with a handful of known exceptions). Help on individual functions can be found in the BioStructures API section or by using ?function_name from within Julia.
Basics
To download a PDB file:
using BioStructures
# Stored in the current working directory by default
downloadpdb("1EN2")To parse a PDB file into a Structure-Model-Chain-Residue-Atom framework:
julia> struc = read("/path/to/pdb/file.pdb", PDBFormat)
MolecularStructure 1EN2.pdb with 1 models, 1 chains (A), 85 residues, 754 atomsmmCIF files can be read into the same data structure with read("/path/to/cif/file.cif", MMCIFFormat). The keyword argument gzip, default false, determines if the file is gzipped. If you want to read an mmCIF file into a dictionary to query yourself (e.g. to access metadata fields), use MMCIFDict:
julia> mmcif_dict = MMCIFDict("/path/to/cif/file.cif")
mmCIF dictionary with 716 fields
julia> mmcif_dict["_entity_src_nat.common_name"]
1-element Array{String,1}:
"great nettle"A MMCIFDict can be accessed in similar ways to a standard dictionary, and if necessary the underlying dictionary of MMCIFDict d can be accessed with d.dict. Note that the values of the dictionary are always an Array{String,1}, even if only one value was read in or the data is numerical.
MMTF files can be read into the same data structure with read("/path/to/mmtf/file.mmtf", MMTFFormat) once you have imported MMTF.jl. The keyword argument gzip, default false, determines if the file is gzipped. In a similar manner to mmCIF dictionaries, a MMTF file can be read into a dictionary with MMTFDict. The values of the dictionary are a variety of types depending on the MMTF specification. To convert a MMCIFDict or MMTFDict to the Structure-Model-Chain-Residue-Atom framework, use the MolecularStructure constructor, e.g. MolecularStructure(mmcif_dict).
The elements of struc can be accessed as follows:
| Command | Returns | Return type |
|---|---|---|
struc[1] | Model 1 | Model |
struc[1]["A"] | Model 1, chain A | Chain |
struc[1]['A'] | Shortcut to above if the chain ID is a single character | Chain |
struc["A"] | The lowest model (model 1), chain A | Chain |
struc["A"]["50"] | Model 1, chain A, residue 50 | AbstractResidue |
struc["A"][50] | Shortcut to above if it is not a hetero residue and the insertion code is blank | AbstractResidue |
struc["A"]["H_90"] | Model 1, chain A, hetero residue 90 | AbstractResidue |
struc["A"][50]["CA"] | Model 1, chain A, residue 50, atom name CA | AbstractAtom |
struc["A"][15]["CG"]['A'] | For disordered atoms, access a specific location | Atom |
You can use begin and end to access the first and last elements, for example struc[1][begin] gets the first chain in model 1. Disordered atoms are stored in a DisorderedAtom container but calls fall back to the default atom, so disorder can be ignored if you are not interested in it. Disordered residues (i.e. point mutations with different residue names) are stored in a DisorderedResidue container. The idea is that disorder will only bother you if you want it to. See the Biopython discussion for more.
Properties can be retrieved as follows:
| Function | Returns | Return type |
|---|---|---|
serial | Serial number of an atom | Int |
atomname | Name of an atom | String |
altlocid | Alternative location ID of an atom | Char |
altlocids | All alternative location IDs in a DisorderedAtom | Array{Char,1} |
BioStructures.x | x coordinate of an atom | Float64 |
BioStructures.y | y coordinate of an atom | Float64 |
BioStructures.z | z coordinate of an atom | Float64 |
coords | coordinates of an atom | Array{Float64,1} |
occupancy | Occupancy of an atom (default is 1.0) | Float64 |
tempfactor | Temperature factor of an atom (default is 0.0) | Float64 |
element | Element of an atom (default is " ") | String |
charge | Charge of an atom (default is " ") | String |
residue | Residue an atom belongs to | Residue |
ishetero | true if the residue or atom is a hetero residue/atom | Bool |
isdisorderedatom | true if the atom is disordered | Bool |
pdbline | PDB ATOM/HETATM record for an atom | String |
resname | Residue name of a residue or atom | String |
resnames | All residue names in a DisorderedResidue | Array{String,1} |
resnumber | Residue number of a residue or atom | Int |
sequentialresidues | Determine if the second residue follows the first in sequence | Bool |
inscode | Insertion code of a residue or atom | Char |
resid | Residue ID of an atom or residue (full=true includes chain) | String |
atomnames | Atom names of the atoms in a residue, sorted by serial | Array{String,1} |
atoms | Dictionary of atoms in a residue | Dict{String,AbstractAtom} |
isdisorderedres | true if the residue has multiple residue names | Bool |
disorderedres | Access a particular residue name in a DisorderedResidue | Residue |
sscode | Secondary structure code of a residue or atom, requires DSSP or STRIDE to be run first | Char |
chain | Chain a residue or atom belongs to | Chain |
chainid | Chain ID of a chain, residue or atom | String |
resids | Sorted residue IDs in a chain | Array{String,1} |
residues | Dictionary of residues in a chain | Dict{String,AbstractResidue} |
model | Model a chain, residue or atom belongs to | Model |
modelnumber | Model number of a model, chain, residue or atom | Int |
chainids | Sorted chain IDs in a model or structure | Array{String,1} |
chains | Dictionary of chains in a model or structure | Dict{String,Chain} |
structure | Structure a model, chain, residue or atom belongs to | MolecularStructure |
structurename | Name of the structure an element belongs to | String |
modelnumbers | Sorted model numbers in a structure | Array{Int,1} |
models | Dictionary of models in a structure | Dict{Int,Model} |
The strip keyword argument determines whether surrounding whitespace is stripped for atomname, element, charge, resname and atomnames (default true).
The coordinates of an atom can be changed using coords! or BioStructures.x!, BioStructures.y! and BioStructures.z!. The chain ID of a chain or residue can be changed using chainid!. Currently these are the only setter functions available.
Manipulating structures
Elements can be looped over to reveal the sub-elements in the correct order:
for mo in struc
for ch in mo
for res in ch
for at in res
# Do something
end
end
end
endModels are ordered numerically; chains are ordered by chain ID character ordering, except the empty chain is last; residues are ordered by residue number and insertion code with hetero residues after standard residues; atoms are ordered by atom serial. Since the ordering of elements is defined you can use the sort function. For example sort(res) sorts a list of residues as described above, or sort(res, by=resname) will sort them alphabetically by residue name.
collect can be used to get arrays of sub-elements. collectatoms, collectresidues, collectchains and collectmodels return arrays of a particular type from a structural element or element array. Since most operations should use a single version of an atom or residue, disordered entities are not expanded by default and only one entity is present in the array. This can be changed by setting expand_disordered to true in collectatoms or collectresidues.
Making selections
There are two ways to select subsets of atoms, residues, chains and models.
Selector functions
Selector functions are passed as additional arguments to the collection functions described above. Only elements that return true when passed to all the selector are retained. For example:
| Command | Action | Return type |
|---|---|---|
collect(struc['A'][50]) | Collect the sub-elements of an element, e.g. atoms from a residue | Array{AbstractAtom,1} |
collectresidues(struc) | Collect the residues of an element | Array{AbstractResidue,1} |
collectatoms(struc) | Collect the atoms of an element | Array{AbstractAtom,1} |
collectatoms(struc, calphaselector) | Collect the Cα atoms of an element | Array{AbstractAtom,1} |
collectatoms(struc, calphaselector, disorderselector) | Collect the disordered Cα atoms of an element | Array{AbstractAtom,1} |
The selector functions available are:
| Function | Acts on | Selects for |
|---|---|---|
standardselector | AbstractAtom or AbstractResidue | Atoms/residues arising from standard (ATOM) records |
heteroselector | AbstractAtom or AbstractResidue | Atoms/residues arising from hetero (HETATM) records |
atomnameselector | AbstractAtom | Atoms with atom name in a given list |
calphaselector | AbstractAtom | Cα atoms |
cbetaselector | AbstractAtom | Cβ atoms, or Cα atoms for glycine residues |
backboneselector | AbstractAtom | Heavy atoms in the protein backbone (CA, N, C and O) |
sidechainselector | AbstractAtom | Atoms not in the protein backbone |
heavyatomselector | AbstractAtom | Non-hydrogen atoms |
hydrogenselector | AbstractAtom | Hydrogen atoms |
resnameselector | AbstractAtom or AbstractResidue | Atoms/residues with residue name in a given list |
proteinselector | AbstractAtom or AbstractResidue | Atoms/residues in a protein or peptide |
acidicresselector | AbstractAtom or AbstractResidue | Acidic amino acids |
aliphaticresselector | AbstractAtom or AbstractResidue | Aliphatic amino acids |
aromaticresselector | AbstractAtom or AbstractResidue | Aromatic amino acids |
basicresselector | AbstractAtom or AbstractResidue | Basic amino acids |
chargedresselector | AbstractAtom or AbstractResidue | Charged amino acids |
neutralresselector | AbstractAtom or AbstractResidue | Neutral amino acids |
hydrophobicresselector | AbstractAtom or AbstractResidue | Hydrophobic amino acids |
polarresselector | AbstractAtom or AbstractResidue | Polar amino acids |
nonpolarresselector | AbstractAtom or AbstractResidue | Non-polar amino acids |
waterselector | AbstractAtom or AbstractResidue | Atoms/residues with residue name HOH |
notwaterselector | AbstractAtom or AbstractResidue | Atoms/residues with residue name not HOH |
disorderselector | AbstractAtom or AbstractResidue | Atoms/residues with alternative locations |
sscodeselector | AbstractAtom or AbstractResidue | Atoms/residues with secondary structure code in a given list |
helixselector | AbstractAtom or AbstractResidue | Atoms/residues that are part of an α-helix |
sheetselector | AbstractAtom or AbstractResidue | Atoms/residues that are part of a β-sheet |
coilselector | AbstractAtom or AbstractResidue | Atoms/residues that are part of a coil |
allselector | Any element | All elements |
To create a new atomnameselector, resnameselector or sscodeselector:
cdeltaselector(at::AbstractAtom) = atomnameselector(at, ["CD"])It is easy to define your own atom, residue, chain or model selectors. The below will collect all atoms with x coordinate less than 0:
xselector(at) = x(at) < 0
collectatoms(struc, xselector)Selectors can be inverted with !, e.g. collectatoms(struc, !xselector). Alternatively, you can use an anonymous function:
collectatoms(struc, at -> x(at) < 0)countatoms, countresidues, countchains and countmodels can be used to count elements with the same selector API. For example:
julia> countatoms(struc)
754
julia> countatoms(struc, calphaselector)
85
julia> countresidues(struc, standardselector)
85
julia> countatoms(struc, expand_disordered=true)
819String selection syntax
BioStructures exports the @sel_str macro that provides a practical way to make selections using a natural selection syntax. It is used as collectatoms(struc, sel"selection string"), where selection string defines the atoms to be selected with the operators and keywords defined below. For example:
julia> struc = retrievepdb("4YC6")
[ Info: Downloading file from PDB: 4YC6
ProteinStructure 4YC6.pdb with 1 models, 8 chains (A,B,C,D,E,F,G,H), 1420 residues, 12271 atoms
julia> collectatoms(struc, sel"name CA and resnumber <= 5")
24-element Vector{AbstractAtom}:
Atom CA with serial 2, coordinates [17.363, 31.409, -27.535]
Atom CA with serial 10, coordinates [20.769, 32.605, -28.801]
⋮
Atom CA with serial 11096, coordinates [-8.996, 6.094, -29.097]
julia> collectchains(struc, sel"chainid <= C")
3-element Vector{Chain}:
Chain A with 285 residues, 147 other molecules, 2450 atoms
Chain B with 70 residues, 42 other molecules, 647 atoms
Chain C with 285 residues, 118 other molecules, 2421 atomsThere are also keywords to select groups with specific properties. For example:
julia> ats = collectatoms(struc, sel"acidic and name N")
188-element Vector{AbstractAtom}:
Atom N with serial 9, coordinates [19.33, 32.429, -28.593]
Atom N with serial 18, coordinates [21.056, 33.428, -26.564]
⋮
Atom N with serial 11603, coordinates [-0.069, 21.516, -32.604]
julia> resname.(ats) # Acidic residues
188-element Vector{SubString{String}}:
"GLU"
"ASP"
⋮
"GLU"
julia> collectresidues(struc, sel"acidic")
188-element Vector{AbstractResidue}:
Residue 2:A with name GLU, 9 atoms
Residue 3:A with name ASP, 8 atoms
⋮
Residue 63:H with name GLU, 9 atomsThe operators currently supported are:
| Operators | Acts on |
|---|---|
=, >, < >=, <= | Properties with real values. |
and, or, not | Selections subsets. |
The keywords supported are:
| Keyword | Input type | Selects for |
|---|---|---|
index | Int | serial |
serial | Int | serial |
resnumber | Int | resnumber |
resnum | Int | resnumber |
resid | Int | resid |
occupancy | Real | occupancy |
beta | Real | tempfactor |
tempfactor | Real | tempfactor |
model | Int | modelnumber |
modelnumber | Int | modelnumber |
name | String | atomname |
atomname | String | atomname |
resname | String | resname |
chain | String | chainid |
chainid | String | chainid |
element | String | element |
inscode | Char | inscode |
sscode | Char | sscode |
x | Real | BioStructures.x |
y | Real | BioStructures.y |
z | Real | BioStructures.z |
standard | - | standardselector |
hetero | - | heteroselector |
backbone | - | backboneselector |
sidechain | - | sidechainselector |
heavyatom | - | heavyatomselector |
hydrogen | - | hydrogenselector |
protein | - | proteinselector |
acidic | - | acidicresselector |
aliphatic | - | aliphaticresselector |
aromatic | - | aromaticresselector |
basic | - | basicresselector |
charged | - | chargedresselector |
neutral | - | neutralresselector |
hydrophobic | - | hydrophobicresselector |
polar | - | polarresselector |
nonpolar | - | nonpolarresselector |
water | - | waterselector |
disordered | - | disorderselector |
helix | - | helixselector |
sheet | - | sheetselector |
coil | - | coilselector |
all | - | allselector |
Sequences and alignments
The amino acid sequence of a protein can be retrieved by passing an element to LongAA with optional residue selectors:
julia> using BioSequences
julia> LongAA(struc['A'], standardselector)
85aa Amino Acid Sequence:
RCGSQGGGSTCPGLRCCSIWGWCGDSEPYCGRTCENKCW…RCGAAVGNPPCGQDRCCSVHGWCGGGNDYCSGGNCQYRCThe gaps keyword argument determines whether to add gaps to the sequence based on missing residue numbers (default true). threeletter_to_aa provides a lookup table of amino acid codes should that be required. See BioSequences.jl and BioAlignments.jl for more on how to deal with sequences. LongAA is an alias for LongSequence{AminoAcidAlphabet}. For example, to see the alignment of CDK1 and CDK2 (this example also makes use of Julia's broadcasting):
julia> using BioSequences, BioAlignments
julia> struc1, struc2 = retrievepdb.(["4YC6", "1HCL"])
2-element Array{MolecularStructure,1}:
MolecularStructure 4YC6.pdb with 1 models, 8 chains (A,B,C,D,E,F,G,H), 1420 residues, 12271 atoms
MolecularStructure 1HCL.pdb with 1 models, 1 chains (A), 294 residues, 2546 atoms
julia> seq1, seq2 = LongAA.([struc1["A"], struc2["A"]], standardselector, gaps=false)
2-element Vector{LongAA}:
MEDYTKIEKIGEGTYGVVYKGRHKTTGQVVAMKKIRLES…SHVKNLDENGLDLLSKMLIYDPAKRISGKMALNHPYFND
MENFQKVEKIGEGTYGVVYKARNKLTGEVVALKKIRTEG…RSLLSQMLHYDPNKRISAKAALAHPFFQDVTKPVPHLRL
julia> scoremodel = AffineGapScoreModel(BLOSUM62, gap_open=-10, gap_extend=-1);
julia> alres = pairalign(GlobalAlignment(), seq1, seq2, scoremodel)
PairwiseAlignmentResult{Int64, LongAA, LongAA}:
score: 945
seq: 1 MEDYTKIEKIGEGTYGVVYKGRHKTTGQVVAMKKIRLESEEEGVPSTAIREISLLKELRH 60
|| | ||||||||||||| | | || ||| |||| | |||||||||||||||| |
ref: 1 MENFQKVEKIGEGTYGVVYKARNKLTGEVVALKKIRTE----GVPSTAIREISLLKELNH 56
seq: 61 PNIVSLQDVLMQDSRLYLIFEFLSMDLKKYLD-SIPPGQYMDSSLVKSYLYQILQGIVFC 119
|||| | || ||| |||| |||| | | | | |||| | ||| ||
ref: 57 PNIVKLLDVIHTENKLYLVFEFLHQDLKKFMDASALTG--IPLPLIKSYLFQLLQGLAFC 114
seq: 120 HSRRVLHRDLKPQNLLIDDKGTIKLADFGLARAFGV----YTHEVVTLWYRSPEVLLGSA 175
|| |||||||||||||| | |||||||||||||| ||||||||||| || |||
ref: 115 HSHRVLHRDLKPQNLLINTEGAIKLADFGLARAFGVPVRTYTHEVVTLWYRAPEILLGCK 174
seq: 176 RYSTPVDIWSIGTIFAELATKKPLFHGDSEIDQLFRIFRALGTPNNEVWPEVESLQDYKN 235
||| ||||| | |||| | || ||||||||||||| |||| ||| | | |||
ref: 175 YYSTAVDIWSLGCIFAEMVTRRALFPGDSEIDQLFRIFRTLGTPDEVVWPGVTSMPDYKP 234
seq: 236 TFPKWKPGSLASHVKNLDENGLDLLSKMLIYDPAKRISGKMALNHPYFND---------- 285
|||| | ||| | ||| || ||| |||| | || || | |
ref: 235 SFPKWARQDFSKVVPPLDEDGRSLLSQMLHYDPNKRISAKAALAHPFFQDVTKPVPHLRL 294
In fact, pairalign is extended to carry out the above steps and return the alignment by calling pairalign(struc1["A"], struc2["A"], standardselector) in this case. scoremodel and aligntype are keyword arguments with the defaults shown above.
Spatial calculations
Various functions are provided to calculate spatial quantities for proteins:
| Command | Returns |
|---|---|
distance | Minimum distance between two elements |
sqdistance | Minimum square distance between two elements |
coordarray | Atomic coordinates in Å of an element as a 2D Array with each column corresponding to one atom |
bondangle | Angle between three atoms |
dihedralangle | Dihedral angle defined by four atoms |
omegaangle | Omega dihedral angle between a residue and the previous residue |
phiangle | Phi dihedral angle between a residue and the previous residue |
psiangle | Psi dihedral angle between a residue and the next residue |
omegaangles | Vector of omega dihedral angles of an element |
phiangles | Vector of phi dihedral angles of an element |
psiangles | Vector of psi dihedral angles of an element |
ramachandranangles | Vectors of phi and psi angles of an element |
ContactMap | ContactMap of two elements, or one element with itself |
DistanceMap | DistanceMap of two elements, or one element with itself |
showcontactmap | Print a representation of a ContactMap to stdout or a specified IO instance |
Transformation | The 3D transformation to map one set of coordinates onto another |
applytransform! | Modify all coordinates in an element according to a transformation |
applytransform | Modify coordinates according to a transformation |
superimpose! | Superimpose one element onto another |
rmsd | RMSD between two elements, with or without superimposition |
displacements | Vector of displacements between two elements, with or without superimposition |
MetaGraph | Construct a MetaGraph of contacting elements (call using Graphs, MetaGraphs first) |
The omegaangle, phiangle and psiangle functions can take either a pair of residues or a chain and a position. The omegaangle and phiangle functions measure the angle between the residue at the given index and the one before. The psiangle function measures between the given index and the one after. For example:
julia> distance(struc['A'][10], struc['A'][20])
10.782158874733762
julia> rad2deg(bondangle(struc['A'][50]["N"], struc['A'][50]["CA"], struc['A'][50]["C"]))
110.77765846083398
julia> rad2deg(dihedralangle(struc['A'][50]["N"], struc['A'][50]["CA"], struc['A'][50]["C"], struc['A'][51]["N"]))
-177.38288114072924
julia> rad2deg(psiangle(struc['A'][50], struc['A'][51]))
-177.38288114072924
julia> rad2deg(psiangle(struc['A'], 50))
-177.38288114072924ContactMap takes in a structural element or a list, such as a Chain or Vector{Atom}, and returns a ContactMap object showing the contacts between the elements for a specified distance. ContactMap can also be given two structural elements as arguments, in which case a non-symmetrical 2D array is returned showing contacts between the elements. The underlying BitArray{2} for ContactMap contacts can be accessed with contacts.data if required.
julia> contacts = ContactMap(collectatoms(struc['A'], cbetaselector), 8.0)
Contact map of size (85, 85)A plot recipe is defined for this so it can shown with Plots.jl:
using Plots
plot(contacts)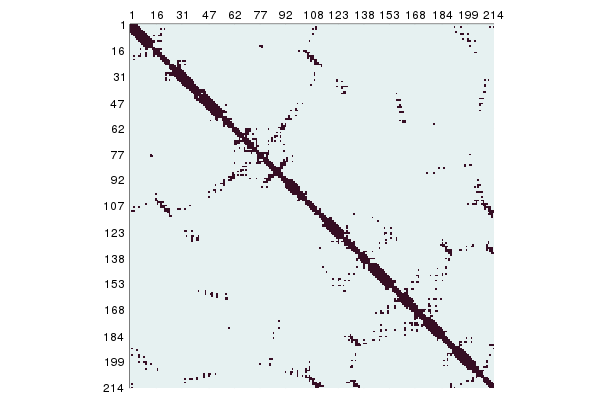
For a quick, text-based representation of a ContactMap use showcontactmap.
DistanceMap works in an analogous way to ContactMap and gives a map of the distances. It can also be plotted:
dists = DistanceMap(collectatoms(struc['A'], cbetaselector))
using Plots
plot(dists)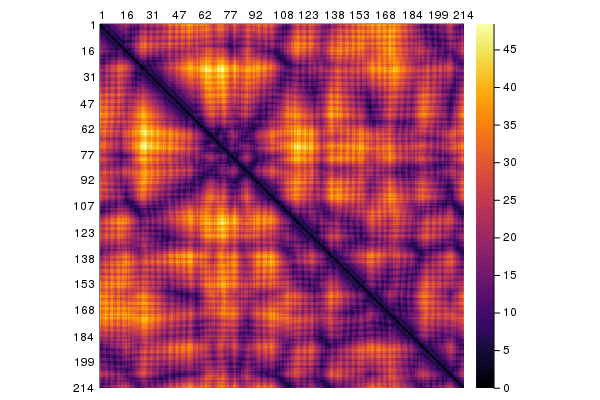
Structural elements can be superimposed, and superposition-dependent properties such as the RMSD can be calculated. To carry out superimposition, BioStructures.jl carries out a sequence alignment and superimposes aligned residues using the Kabsch algorithm. For example:
using BioSequences, BioAlignments
# Change the coordinates of element 1 to superimpose it onto element 2
# Do sequence alignment with standard residues and calculate the transformation with Cα atoms (the default)
superimpose!(el1, el2, standardselector)
# The transformation object for the above superimposition
Transformation(el1, el2, standardselector)
# Calculate the transformation with backbone atoms
superimpose!(el1, el2, standardselector, alignatoms=backboneselector)
# Calculate RMSD on Cα atoms (the default) after superimposition
rmsd(el1, el2, standardselector)
# Superimpose based on backbone atoms and calculate RMSD based on Cβ atoms
rmsd(el1, el2, standardselector, alignatoms=backboneselector, rmsdatoms=cbetaselector)
# Do not do a superimposition - assumes the elements are already superimposed
rmsd(el1, el2, standardselector, superimpose=false)displacements is used in a similar way to rmsd but returns the vector of distances for each superimposed atom. dispatoms selects the atoms to calculate the displacements on.
These transformation functions may be useful beyond the context of protein structures. For example, Transformation(c1, c2) calculates the transformation to map one set of coordinates to another. The coordinate sets must be the same size and have the number of dimensions in the first axis and the number of points in the second axis.
The contacting elements in a molecular structure form a graph, and this can be retrieved using MetaGraph. This extends MetaGraph from MetaGraphs.jl, allowing you to use all the graph analysis tools in Graphs.jl. For example:
julia> using Graphs, MetaGraphs
julia> mg = MetaGraph(collectatoms(struc["A"], cbetaselector), 8.0)
{85, 423} undirected Int64 metagraph with Float64 weights defined by :weight (default weight 1.0)
julia> nv(mg)
85
julia> ne(mg)
423
julia> get_prop(mg, :contactdist)
8.0
julia> mg[10, :element]
Atom CB with serial 71, coordinates [-3.766, 4.031, 23.526]See the Graphs docs for details on how to calculate properties such as shortest paths, centrality measures, community detection and more. Similar to ContactMap, contacts are found between any element type passed in. So if you wanted the graph of chain contacts in a protein complex you could give a Model as the first argument.
Assigning secondary structure
The secondary structure code of a residue or atom can be accessed after assigning the secondary structure using DSSP or STRIDE. To assign secondary structure when reading the structure:
# Assign secondary structure using DSSP
read("/path/to/pdb/file.pdb", PDBFormat, run_dssp=true)
# Assign secondary structure using STRIDE
read("/path/to/pdb/file.pdb", PDBFormat, run_stride=true)rundssp!, runstride!, rundssp and runstride can also be used to assign secondary structure to a MolecularStructure or Model:
rundssp!(struc)
runstride!(struc)The assignment process may fail if the structure is too large, since we use an intermediate PDB file where the atom serial cannot exceed 99999 and the chain ID must be a single character. To get access to the secondary structure code of a residue or atom as a Char:
sscode(res)
sscode(at)Or for the whole structure:
sscode.(collectresidues(struc))The secondary structure code of a residue can be changed using sscode!. rundssp and runstride can also be run directly on structure files:
rundssp("/path/to/pdb/file.pdb", "out.dssp") # Also works with mmCIF files
runstride("/path/to/pdb/file.pdb", "out.stride")See the documentation for DSSP_jll and STRIDE_jll, and also ProteinSecondaryStructures.jl, for other ways to run these programs.
Downloading PDB files
To download a PDB file to a specified directory:
downloadpdb("1EN2", dir="path/to/pdb/directory")To download multiple PDB files to a specified directory:
downloadpdb(["1EN2", "1ALW", "1AKE"], dir="path/to/pdb/directory")To download a PDB file in PDB, XML, mmCIF or MMTF format use the format argument:
# To get mmCIF
downloadpdb("1ALW", dir="path/to/pdb/directory", format=MMCIFFormat)
# To get XML
downloadpdb("1ALW", dir="path/to/pdb/directory", format=PDBXMLFormat)To apply a function to a downloaded file and delete the file afterwards:
downloadpdb(f, "1ALW")Or, using Julia's do syntax:
downloadpdb("1ALW") do fp
s = read(fp, PDBFormat)
# Do something
endNote that some PDB entries, e.g. large viral assemblies, are not available as PDB format files. In this case download the mmCIF file or MMTF file instead.
Reading PDB files
To parse an existing PDB file into a Structure-Model-Chain-Residue-Atom framework:
julia> struc = read("/path/to/pdb/file.pdb", PDBFormat)
MolecularStructure 1EN2.pdb with 1 models, 1 chains (A), 85 residues, 754 atomsRead a mmCIF/MMTF file instead by replacing PDBFormat with MMCIFFormat/MMTFFormat. Various options can be set through optional keyword arguments when parsing PDB/mmCIF/MMTF files:
| Keyword Argument | Description |
|---|---|
structure_name::AbstractString | The name given to the returned MolecularStructure; defaults to the file name |
remove_disorder::Bool=false | Whether to remove atoms with alt loc ID not ' ' or 'A' |
read_std_atoms::Bool=true | Whether to read standard ATOM records |
read_het_atoms::Bool=true | Whether to read HETATOM records |
gzip::Bool=false | Whether the file is gzipped (MMTF and mmCIF files only) |
Use retrievepdb to download and parse a PDB file into a Structure-Model-Chain-Residue-Atom framework in a single line:
julia> struc = retrievepdb("1ALW", dir="path/to/pdb/directory")
INFO: Downloading PDB: 1ALW
MolecularStructure 1ALW.pdb with 1 models, 2 chains (A,B), 346 residues, 2928 atomsIf you prefer to work with data frames rather than the data structures in BioStructures, the DataFrame constructor from DataFrames.jl has been extended to construct relevant data frames from lists of atoms or residues:
julia> using DataFrames
julia> df = DataFrame(collectatoms(struc));
julia> first(df, 3)
3×17 DataFrame. Omitted printing of 5 columns
│ Row │ ishetero │ serial │ atomname │ altlocid │ resname │ chainid │ resnumber │ inscode │ x │ y │ z │ occupancy │
│ │ Bool │ Int64 │ String │ Char │ String │ String │ Int64 │ Char │ Float64 │ Float64 │ Float64 │ Float64 │
├─────┼──────────┼────────┼──────────┼──────────┼─────────┼─────────┼───────────┼─────────┼─────────┼─────────┼─────────┼───────────┤
│ 1 │ false │ 1 │ N │ ' ' │ GLU │ A │ 94 │ ' ' │ 15.637 │ -47.066 │ 18.179 │ 1.0 │
│ 2 │ false │ 2 │ CA │ ' ' │ GLU │ A │ 94 │ ' ' │ 14.439 │ -47.978 │ 18.304 │ 1.0 │
│ 3 │ false │ 3 │ C │ ' ' │ GLU │ A │ 94 │ ' ' │ 14.141 │ -48.183 │ 19.736 │ 1.0 │
julia> df = DataFrame(collectresidues(struc));
julia> first(df, 3)
3×8 DataFrame
│ Row │ ishetero │ resname │ chainid │ resnumber │ inscode │ countatoms │ modelnumber │ isdisorderedres │
│ │ Bool │ String │ String │ Int64 │ Char │ Int64 │ Int64 │ Bool │
├─────┼──────────┼─────────┼─────────┼───────────┼─────────┼────────────┼─────────────┼─────────────────┤
│ 1 │ false │ GLU │ A │ 94 │ ' ' │ 9 │ 1 │ false │
│ 2 │ false │ GLU │ A │ 95 │ ' ' │ 9 │ 1 │ false │
│ 3 │ false │ VAL │ A │ 96 │ ' ' │ 7 │ 1 │ false │As with file writing disordered entities are expanded by default but this can be changed by setting expand_disordered to false.
Reading multiple mmCIF data blocks
You can read and write files containing multiple mmCIF data blocks (equivalent to a MMCIFDict in this package) with the readmultimmcif and writemultimmcif functions. An example of such a file is the PDB's chemical component dictionary.
julia> ccd = readmultimmcif("components.cif.gz"; gzip=true);
julia> ccd["2W4"]
mmCIF dictionary with 64 fieldsWriting PDB files
PDB format files can be written:
writepdb("1EN2_out.pdb", struc)Any element type can be given as input to writepdb. The first argument can also be a stream. Atom selectors can also be given as additional arguments:
# Only backbone atoms are written out
writepdb("1EN2_out.pdb", struc, backboneselector)To write mmCIF format files, use the writemmcif function with similar arguments. The gzip keyword argument, default false, determines whether to gzip the written file. A MMCIFDict can also be written using writemmcif:
writemmcif("1EN2_out.dic", mmcif_dict)To write out a MMTF file, import MMTF.jl and use the writemmtf function with any element type or a MMTFDict as an argument. The gzip keyword argument, default false, determines whether to gzip the written file.
Unlike for the collection functions, expand_disordered is set to true when writing files as it is usually desirable to retain all entities. Set expand_disordered to false to not write out more than one atom or residue at each location.
Multi-character chain IDs can be written to mmCIF and MMTF files but will throw an error when written to a PDB file as the PDB file format only has one character allocated to the chain ID.
If you want the PDB record line for an AbstractAtom, use pdbline. For example:
julia> pdbline(at)
"HETATM 101 C A X B 20 10.500 20.123 -5.123 0.50 50.13 C1+"If you want to generate a PDB record line from values directly, do so using an AtomRecord:
julia> pdbline(AtomRecord(false, 669, "CA", ' ', "ILE", "A", 90, ' ', [31.743, 33.11, 31.221], 1.00, 25.76, "C", ""))
"ATOM 669 CA ILE A 90 31.743 33.110 31.221 1.00 25.76 C "This can be useful when writing PDB files from your own data structures.
RCSB PDB utility functions
To get the list of all PDB entries:
l = pdbentrylist()To download the entire RCSB PDB database in your preferred file format:
downloadentirepdb(dir="path/to/pdb/directory", format=MMTFFormat)This operation takes a lot of disk space and time to complete, depending on internet connection.
To update your local PDB directory based on the weekly status list of new, modified and obsolete PDB files from the RCSB server:
updatelocalpdb(dir="path/to/pdb/directory", format=MMTFFormat)Obsolete PDB files are stored in the auto-generated obsolete directory inside the specified local PDB directory.
To maintain a local copy of the entire RCSB PDB database, run the downloadentirepdb function once to download all PDB files and set up a CRON job or similar to run updatelocalpdb function once a week to keep the local PDB directory up to date with the RCSB server.
There are a few more functions that may be useful:
| Function | Returns | Return type |
|---|---|---|
pdbstatuslist | List of PDB entries from a specified RCSB weekly status list URL | Array{String,1} |
pdbrecentchanges | Added, modified and obsolete PDB lists from the recent RCSB weekly status files | Tuple{Array{String,1},Array{String,1}, Array{String,1}} |
pdbobsoletelist | List of all obsolete PDB entries | Array{String,1} |
downloadallobsoletepdb | Downloads all obsolete PDB files from the RCSB PDB server | Array{String,1} |
Visualising structures
The Bio3DView.jl package can be used to visualise molecular structures. For example:
using Bio3DView
using Blink
viewpdb("1CRN")Use the mouse to move and zoom the images. You can view BioStructures data types:
struc = retrievepdb("1AKE")
viewstruc(struc['A'], surface=Surface(Dict("colorscheme" => "greenCarbon")))See the Bio3DView.jl tutorial for more information. BioMakie.jl can also be used to visualise BioStructures objects.
Design decisions
The relationship between different types in BioStructures is shown below:

The design is based on Biopython, and has the intention of representing the complexity of the data in the PDB without it getting in the way of users. This hierarchical approach differs from some packages that represent structures as lists of either atoms or residues. Note that it is possible to store non-biopolymer molecules in this representation, and there are many such examples in the PDB. In general chemical terms: MolecularStructure is analogous to ensemble, Model to conformation, Chain to molecule and Residue to monomeric unit when relevant.
The aim of BioStructures is not so much to read in the rows of a structure file, but to unambiguously represent the molecules contained within the file. This makes operations such as converting between file formats easier, at the cost of some complexity and occasional limits on the ability to read in files with format violations. For example, we have no way to represent multiple copies of the same atom with the same alt loc ID, as they would be placed at the same spot in the hierarchy. Such files often lead to silent errors, however, so we recommend users follow the appropriate format guidelines. The mmCIF format is able to store arbitrary data systematically if required.
Related software
Other packages in the Julia ecosystem that deal with structural bioinformatics or related fields include:
- MIToS.jl - protein sequence and structure analysis.
- PDBTools.jl - read and write PDB files.
- PdbTool.jl - read and work with PDB files.
- Chemfiles.jl - read and write various chemistry trajectory files.
- Bio3DView.jl - view molecular structures (see Visualising structures).
- BioMakie.jl - view molecular structures and sequence alignments.
- ProtPlot.jl - view protein ribbons with Makie.jl.
- ProteinSecondaryStructures.jl - parses DSSP and STRIDE outputs.
- MMTF.jl - read and write MMTF files. BioStructures.jl builds on top of MMTF.jl.
- ProteinEnsembles.jl - model ensembles of protein structures.
- Molly.jl - molecular dynamics in Julia.