Schelling's segregation model
In this introductory example we demonstrate Agents.jl's architecture and features through building the following definition of Schelling's segregation model:
- Agents belong to one of two groups (0 or 1).
- The agents live in a two-dimensional Moore grid (8 neighbors per node).
- If an agent is in the same group with at least three neighbors, then it is happy.
- If an agent is unhappy, it keeps moving to new locations until it is happy.
Schelling's model shows that even small preferences of agents to have neighbors belonging to the same group (e.g. preferring that at least 30% of neighbors to be in the same group) could lead to total segregation of neighborhoods.
This model is also available as Models.schelling.
Defining the agent type
using Agents, AgentsPlots
mutable struct SchellingAgent <: AbstractAgent
id::Int # The identifier number of the agent
pos::Tuple{Int,Int} # The x, y location of the agent on a 2D grid
mood::Bool # whether the agent is happy in its node. (true = happy)
group::Int # The group of the agent, determines mood as it interacts with neighbors
endNotice that the position of this Agent type is a Tuple{Int,Int} because we will use a GridSpace.
We added two more fields for this model, namely a mood field which will store true for a happy agent and false for an unhappy one, and an group field which stores 0 or 1 representing two groups.
Creating a space
For this example, we will be using a Moore 2D grid, e.g.
space = GridSpace((10, 10), moore = true)GridSpace with 100 nodes and 342 edges
Creating an ABM
To make our model we follow the instructions of AgentBasedModel. We also want to include a property min_to_be_happy in our model, and so we have:
properties = Dict(:min_to_be_happy => 3)
schelling = ABM(SchellingAgent, space; properties = properties)AgentBasedModel with 0 agents of type SchellingAgent space: GridSpace with 100 nodes and 342 edges scheduler: fastest properties: Dict(:min_to_be_happy => 3)
Here we used the default scheduler (which is also the fastest one) to create the model. We could instead try to activate the agents according to their property :group, so that all agents of group 1 act first. We would then use the scheduler property_activation like so:
schelling2 = ABM(
SchellingAgent,
space;
properties = properties,
scheduler = property_activation(:group),
)AgentBasedModel with 0 agents of type SchellingAgent space: GridSpace with 100 nodes and 342 edges scheduler: by_property properties: Dict(:min_to_be_happy => 3)
Notice that property_activation accepts an argument and returns a function, which is why we didn't just give property_activation to scheduler.
Creating the ABM through a function
Here we put the model instantiation in a function so that it will be easy to recreate the model and change its parameters.
In addition, inside this function, we populate the model with some agents. We also change the scheduler to random_activation. Because the function is defined based on keywords, it will be of further use in paramscan below.
function initialize(; numagents = 320, griddims = (20, 20), min_to_be_happy = 3)
space = GridSpace(griddims, moore = true)
properties = Dict(:min_to_be_happy => min_to_be_happy)
model = ABM(SchellingAgent, space;
properties = properties, scheduler = random_activation)
# populate the model with agents, adding equal amount of the two types of agents
# at random positions in the model
for n in 1:numagents
agent = SchellingAgent(n, (1, 1), false, n < numagents / 2 ? 1 : 2)
add_agent_single!(agent, model)
end
return model
endNotice that the position that an agent is initialized does not matter in this example. This is because we use add_agent_single!, which places the agent in a random, empty location on the grid, thus updating its position.
Defining a step function
Finally, we define a step function to determine what happens to an agent when activated.
function agent_step!(agent, model)
agent.mood == true && return # do nothing if already happy
minhappy = model.min_to_be_happy
neighbor_cells = node_neighbors(agent, model)
count_neighbors_same_group = 0
# For each neighbor, get group and compare to current agent's group
# and increment count_neighbors_same_group as appropriately.
for neighbor_cell in neighbor_cells
node_contents = get_node_contents(neighbor_cell, model)
# Skip iteration if the node is empty.
length(node_contents) == 0 && continue
# Otherwise, get the first agent in the node...
agent_id = node_contents[1]
# ...and increment count_neighbors_same_group if the neighbor's group is
# the same.
neighbor_agent_group = model[agent_id].group
if neighbor_agent_group == agent.group
count_neighbors_same_group += 1
end
end
# After counting the neighbors, decide whether or not to move the agent.
# If count_neighbors_same_group is at least the min_to_be_happy, set the
# mood to true. Otherwise, move the agent to a random node.
if count_neighbors_same_group ≥ minhappy
agent.mood = true
else
move_agent_single!(agent, model)
end
return
endFor the purpose of this implementation of Schelling's segregation model, we only need an agent step function.
When defining agent_step!, we used some of the built-in functions of Agents.jl, such as node_neighbors that returns the neighboring nodes of the node on which the agent resides, get_node_contents that returns the IDs of the agents on a given node, and move_agent_single! which moves agents to random empty nodes on the grid. A full list of built-in functions and their explanations are available in the API page.
Stepping the model
Let's initialize the model with 370 agents on a 20 by 20 grid.
model = initialize()AgentBasedModel with 320 agents of type SchellingAgent space: GridSpace with 400 nodes and 1482 edges scheduler: random_activation properties: Dict(:min_to_be_happy => 3)
We can advance the model one step
step!(model, agent_step!)Or for three steps
step!(model, agent_step!, 3)Running the model and collecting data
We can use the run! function with keywords to run the model for multiple steps and collect values of our desired fields from every agent and put these data in a DataFrame object. We define vector of Symbols for the agent fields that we want to collect as data
adata = [:pos, :mood, :group]
model = initialize()
data, _ = run!(model, agent_step!, 5; adata = adata)
data[1:10, :] # print only a few rows10 rows × 5 columns
| step | id | pos | mood | group | |
|---|---|---|---|---|---|
| Int64 | Int64 | Tuple… | Bool | Int64 | |
| 1 | 0 | 1 | (4, 8) | 0 | 1 |
| 2 | 0 | 2 | (8, 12) | 0 | 1 |
| 3 | 0 | 3 | (17, 16) | 0 | 1 |
| 4 | 0 | 4 | (20, 5) | 0 | 1 |
| 5 | 0 | 5 | (18, 12) | 0 | 1 |
| 6 | 0 | 6 | (9, 12) | 0 | 1 |
| 7 | 0 | 7 | (18, 13) | 0 | 1 |
| 8 | 0 | 8 | (6, 3) | 0 | 1 |
| 9 | 0 | 9 | (19, 2) | 0 | 1 |
| 10 | 0 | 10 | (5, 13) | 0 | 1 |
We could also use functions in adata, for example we can define
x(agent) = agent.pos[1]
model = initialize()
adata = [x, :mood, :group]
data, _ = run!(model, agent_step!, 5; adata = adata)
data[1:10, :]10 rows × 5 columns
| step | id | x | mood | group | |
|---|---|---|---|---|---|
| Int64 | Int64 | Int64 | Bool | Int64 | |
| 1 | 0 | 1 | 3 | 0 | 1 |
| 2 | 0 | 2 | 15 | 0 | 1 |
| 3 | 0 | 3 | 8 | 0 | 1 |
| 4 | 0 | 4 | 11 | 0 | 1 |
| 5 | 0 | 5 | 2 | 0 | 1 |
| 6 | 0 | 6 | 20 | 0 | 1 |
| 7 | 0 | 7 | 5 | 0 | 1 |
| 8 | 0 | 8 | 19 | 0 | 1 |
| 9 | 0 | 9 | 3 | 0 | 1 |
| 10 | 0 | 10 | 12 | 0 | 1 |
With the above adata vector, we collected all agent's data. We can instead collect aggregated data for the agents. For example, let's only get the number of happy individuals, and the maximum of the "x" (not very interesting, but anyway!)
model = initialize();
adata = [(:mood, sum), (x, maximum)]
data, _ = run!(model, agent_step!, 5; adata = adata)
data6 rows × 3 columns
| step | sum_mood | maximum_x | |
|---|---|---|---|
| Int64 | Int64 | Int64 | |
| 1 | 0 | 0 | 20 |
| 2 | 1 | 212 | 20 |
| 3 | 2 | 281 | 20 |
| 4 | 3 | 297 | 20 |
| 5 | 4 | 306 | 20 |
| 6 | 5 | 312 | 20 |
Other examples in the documentation are more realistic, with a much more meaningful collected data. Don't forget to use the function aggname to access the columns of the resulting dataframe by name.
Visualizing the data
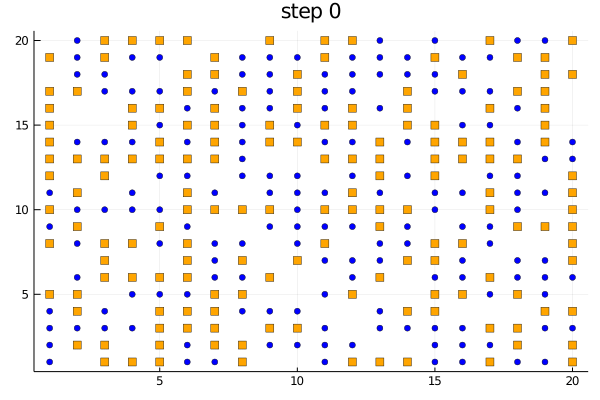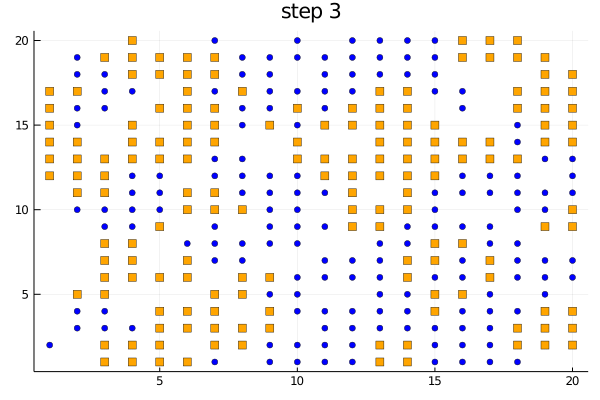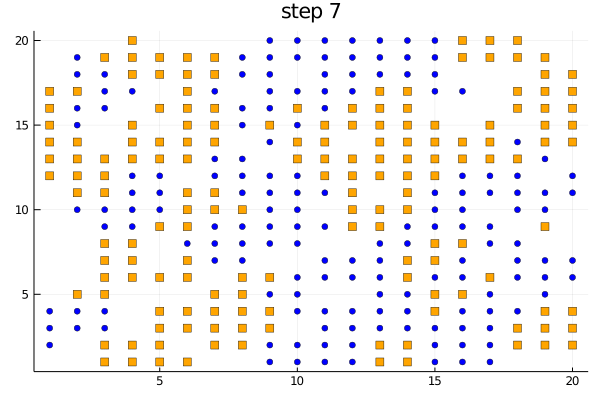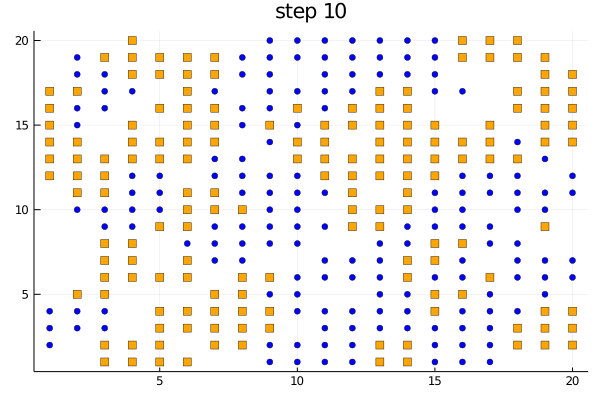
We can use the plotabm function to plot the distribution of agents on a 2D grid at every generation, via the AgentsPlots package. Let's color the two groups orange and blue and make one a square and the other a circle.
groupcolor(a) = a.group == 1 ? :blue : :orange
groupmarker(a) = a.group == 1 ? :circle : :square
plotabm(model; ac = groupcolor, am = groupmarker, as = 4)Animating the evolution
The function plotabm can be used to make your own animations
model = initialize();
anim = @animate for i in 0:10
p1 = plotabm(model; ac = groupcolor, am = groupmarker, as = 4)
title!(p1, "step $(i)")
step!(model, agent_step!, 1)
end
gif(anim, "schelling.gif", fps = 2)
Replicates and parallel computing
We can run replicates of a simulation and collect all of them in a single DataFrame. To that end, we only need to specify replicates in the run! function:
model = initialize(numagents = 370, griddims = (20, 20), min_to_be_happy = 3)
data, _ = run!(model, agent_step!, 5; adata = adata, replicates = 3)
data[(end - 10):end, :]11 rows × 4 columns
| step | sum_mood | maximum_x | replicate | |
|---|---|---|---|---|
| Int64 | Int64 | Int64 | Int64 | |
| 1 | 1 | 269 | 20 | 2 |
| 2 | 2 | 323 | 20 | 2 |
| 3 | 3 | 344 | 20 | 2 |
| 4 | 4 | 355 | 20 | 2 |
| 5 | 5 | 361 | 20 | 2 |
| 6 | 0 | 0 | 20 | 3 |
| 7 | 1 | 272 | 20 | 3 |
| 8 | 2 | 327 | 20 | 3 |
| 9 | 3 | 345 | 20 | 3 |
| 10 | 4 | 358 | 20 | 3 |
| 11 | 5 | 364 | 20 | 3 |
It is possible to run the replicates in parallel. For that, we should start julia with julia -p n where is the number of processing cores. Alternatively, we can define the number of cores from within a Julia session:
using Distributed
addprocs(4)For distributed computing to work, all definitions must be preceded with @everywhere, e.g.
@everywhere using Agents
@everywhere mutable struct SchellingAgent ...Then we can tell the run! function to run replicates in parallel:
data, _ = run!(model, agent_step!, 2, adata=adata,
replicates=5, parallel=true)Scanning parameter ranges
We often are interested in the effect of different parameters on the behavior of an agent-based model. Agents.jl provides the function paramscan to automatically explore the effect of different parameter values.
We have already defined our model initialization function as initialize. We now also define a processing function, that returns the percentage of happy agents:
happyperc(moods) = count(x -> x == true, moods) / length(moods)
adata = [(:mood, happyperc)]
parameters =
Dict(:min_to_be_happy => collect(2:5), :numagents => [200, 300], :griddims => (20, 20))
data, _ = paramscan(parameters, initialize; adata = adata, n = 3, agent_step! = agent_step!)
data32 rows × 4 columns
| step | happyperc_mood | min_to_be_happy | numagents | |
|---|---|---|---|---|
| Int64 | Float64 | Int64 | Int64 | |
| 1 | 0 | 0.0 | 2 | 200 |
| 2 | 1 | 0.61 | 2 | 200 |
| 3 | 2 | 0.845 | 2 | 200 |
| 4 | 3 | 0.935 | 2 | 200 |
| 5 | 0 | 0.0 | 3 | 200 |
| 6 | 1 | 0.335 | 3 | 200 |
| 7 | 2 | 0.575 | 3 | 200 |
| 8 | 3 | 0.71 | 3 | 200 |
| 9 | 0 | 0.0 | 4 | 200 |
| 10 | 1 | 0.14 | 4 | 200 |
| 11 | 2 | 0.24 | 4 | 200 |
| 12 | 3 | 0.3 | 4 | 200 |
| 13 | 0 | 0.0 | 5 | 200 |
| 14 | 1 | 0.025 | 5 | 200 |
| 15 | 2 | 0.035 | 5 | 200 |
| 16 | 3 | 0.07 | 5 | 200 |
| 17 | 0 | 0.0 | 2 | 300 |
| 18 | 1 | 0.846667 | 2 | 300 |
| 19 | 2 | 0.963333 | 2 | 300 |
| 20 | 3 | 0.976667 | 2 | 300 |
| 21 | 0 | 0.0 | 3 | 300 |
| 22 | 1 | 0.623333 | 3 | 300 |
| 23 | 2 | 0.83 | 3 | 300 |
| 24 | 3 | 0.913333 | 3 | 300 |
| 25 | 0 | 0.0 | 4 | 300 |
| 26 | 1 | 0.4 | 4 | 300 |
| 27 | 2 | 0.61 | 4 | 300 |
| 28 | 3 | 0.783333 | 4 | 300 |
| 29 | 0 | 0.0 | 5 | 300 |
| 30 | 1 | 0.173333 | 5 | 300 |
| 31 | 2 | 0.276667 | 5 | 300 |
| 32 | 3 | 0.44 | 5 | 300 |
paramscan also allows running replicates per parameter setting:
data, _ = paramscan(
parameters,
initialize;
adata = adata,
n = 3,
agent_step! = agent_step!,
replicates = 3,
)
data[(end - 10):end, :]11 rows × 5 columns
| step | happyperc_mood | replicate | min_to_be_happy | numagents | |
|---|---|---|---|---|---|
| Int64 | Float64 | Int64 | Int64 | Int64 | |
| 1 | 1 | 0.17 | 1 | 5 | 300 |
| 2 | 2 | 0.316667 | 1 | 5 | 300 |
| 3 | 3 | 0.423333 | 1 | 5 | 300 |
| 4 | 0 | 0.0 | 2 | 5 | 300 |
| 5 | 1 | 0.176667 | 2 | 5 | 300 |
| 6 | 2 | 0.35 | 2 | 5 | 300 |
| 7 | 3 | 0.433333 | 2 | 5 | 300 |
| 8 | 0 | 0.0 | 3 | 5 | 300 |
| 9 | 1 | 0.163333 | 3 | 5 | 300 |
| 10 | 2 | 0.363333 | 3 | 5 | 300 |
| 11 | 3 | 0.443333 | 3 | 5 | 300 |
We can combine all replicates with an aggregating function, such as mean, using the groupby and combine functions from the DataFrames package:
using DataFrames: groupby, combine, Not, select!
using Statistics: mean
gd = groupby(data,[:step, :min_to_be_happy, :numagents])
data_mean = combine(gd,[:happyperc_mood,:replicate] .=> mean)
select!(data_mean, Not(:replicate_mean))32 rows × 4 columns
| step | min_to_be_happy | numagents | happyperc_mood_mean | |
|---|---|---|---|---|
| Int64 | Int64 | Int64 | Float64 | |
| 1 | 0 | 2 | 200 | 0.0 |
| 2 | 1 | 2 | 200 | 0.626667 |
| 3 | 2 | 2 | 200 | 0.84 |
| 4 | 3 | 2 | 200 | 0.933333 |
| 5 | 0 | 3 | 200 | 0.0 |
| 6 | 1 | 3 | 200 | 0.311667 |
| 7 | 2 | 3 | 200 | 0.586667 |
| 8 | 3 | 3 | 200 | 0.701667 |
| 9 | 0 | 4 | 200 | 0.0 |
| 10 | 1 | 4 | 200 | 0.14 |
| 11 | 2 | 4 | 200 | 0.301667 |
| 12 | 3 | 4 | 200 | 0.391667 |
| 13 | 0 | 5 | 200 | 0.0 |
| 14 | 1 | 5 | 200 | 0.04 |
| 15 | 2 | 5 | 200 | 0.0766667 |
| 16 | 3 | 5 | 200 | 0.111667 |
| 17 | 0 | 2 | 300 | 0.0 |
| 18 | 1 | 2 | 300 | 0.838889 |
| 19 | 2 | 2 | 300 | 0.957778 |
| 20 | 3 | 2 | 300 | 0.986667 |
| 21 | 0 | 3 | 300 | 0.0 |
| 22 | 1 | 3 | 300 | 0.606667 |
| 23 | 2 | 3 | 300 | 0.826667 |
| 24 | 3 | 3 | 300 | 0.901111 |
| 25 | 0 | 4 | 300 | 0.0 |
| 26 | 1 | 4 | 300 | 0.295556 |
| 27 | 2 | 4 | 300 | 0.544444 |
| 28 | 3 | 4 | 300 | 0.678889 |
| 29 | 0 | 5 | 300 | 0.0 |
| 30 | 1 | 5 | 300 | 0.17 |
| 31 | 2 | 5 | 300 | 0.343333 |
| 32 | 3 | 5 | 300 | 0.433333 |
Note that the second argument takes the column names on which to split the data, i.e., it denotes which columns should not be aggregated. It should include the :step column and any parameter that changes among simulations. But it should not include the :replicate column. So in principle what we are doing here is simply averaging our result across the replicates.
Launching the interactive application
Given the definitions we have already created for a normal study of the Schelling model, it is almost trivial to launch an interactive application for it. First, we load InteractiveChaos to access interactive_abm
using InteractiveChaos
using GLMakie # we choose OpenGL as plotting backendThen, we define a dictionary that maps some model-level parameters to a range of potential values, so that we can interactively change them.
parange = Dict(:min_to_be_happy => 0:8)Dict{Symbol,UnitRange{Int64}} with 1 entry:
:min_to_be_happy => 0:8Due to the different plotting backend (Plots.jl vs Makie.jl) we redefine some of the plotting functions (in the near future this won't be necessary, as everything will be Makie.jl based)
groupcolor(a) = a.group == 1 ? :blue : :orange
groupmarker(a) = a.group == 1 ? :circle : :rectgroupmarker (generic function with 1 method)
We define the alabels so that we can simple see the plotted timeseries with a shorter name (since the defaults can get large)
adata = [(:mood, sum), (x, mean)]
alabels = ["happy", "avg. x"]
model = initialize(; numagents = 300) # fresh model, noone happyAgentBasedModel with 300 agents of type SchellingAgent space: GridSpace with 400 nodes and 1482 edges scheduler: random_activation properties: Dict(:min_to_be_happy => 3)
scene, adf, modeldf =
interactive_abm(model, agent_step!, dummystep, parange;
ac = groupcolor, am = groupmarker, as = 1,
adata = adata, alabels = alabels)