Shared Memory Across Kernels
In many use cases, we want to share data across multiple kernels. For example, if we want to design several custom operators for finite element analysis (e.g., one for assembling, one for solving the linear system and one for performing Newton's iteration), we might want to share the geometric data such as nodes and element connectivity matrices. This can be done by the share memory mechanism of dynamical shared libraries.
Dynamical shared libraries have the following property: in Unix-like environments, shared libries export all extern global variables. That is, multiple shared libraries can change the same variable as long as the variable is marked as extern. However, extern variable itself is not a definition but only a declaration. The variable should be defined in one and only one shared library.
Therefore, when we design custom operators and want to have global variables that will be reused by multiple custom kernels (each constitutes a separate dynamical shared library), we can link each of them to a "data storage" shared library. The "data storage" shared library should contain the definition of the global variable to be shared among those kernels.
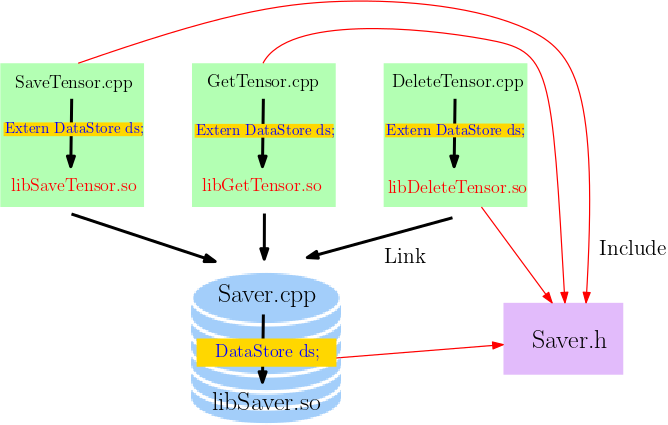
As an example, consider we want to share Float64 vectors (with String keys). The data structure of the storage is given in Saver.h
#include <map>
#include <string>
#include <vector>
struct DataStore
{
std::map<std::string, std::vector<double>> vdata;
};
extern DataStore ds;Note we include extern DataStore ds; for convenience: we can include Saver.h for our custom operator kernels so that we have access to ds.
Additionally, in Saver.cpp, we define ds
#include "Saver.h"
DataStore ds;Now we can compile a dynamical shared library Saver.so (or Saver.dylib) with Saver.h and Saver.cpp. For all the other kernel implementation, we can include the header file Saver.h and link to Saver.so (or Saver.dylib) during compilation.
We show an example for storing, querying and deleting $10\times 1$Float64 vectors with this technique. The main files are
SaverTensor.cpp
#include "Saver.h"
#include "tensorflow/core/framework/op_kernel.h"
#include "tensorflow/core/framework/tensor_shape.h"
#include "tensorflow/core/platform/default/logging.h"
#include "tensorflow/core/framework/shape_inference.h"
#include<cmath>
#include<string>
#include<eigen3/Eigen/Core>
using std::string;
using namespace tensorflow;
REGISTER_OP("SaveTensor")
.Input("handle : string")
.Input("val : double")
.Output("out : string")
.SetShapeFn([](::tensorflow::shape_inference::InferenceContext* c) {
shape_inference::ShapeHandle handle_shape;
TF_RETURN_IF_ERROR(c->WithRank(c->input(0), 0, &handle_shape));
shape_inference::ShapeHandle val_shape;
TF_RETURN_IF_ERROR(c->WithRank(c->input(1), 1, &val_shape));
c->set_output(0, c->Scalar());
return Status::OK();
});
class SaveTensorOp : public OpKernel {
private:
public:
explicit SaveTensorOp(OpKernelConstruction* context) : OpKernel(context) {
}
void Compute(OpKernelContext* context) override {
DCHECK_EQ(2, context->num_inputs());
const Tensor& handle = context->input(0);
const Tensor& val = context->input(1);
const TensorShape& val_shape = val.shape();
DCHECK_EQ(val_shape.dims(), 1);
// extra check
// create output shape
TensorShape out_shape({});
// create output tensor
Tensor* out = NULL;
OP_REQUIRES_OK(context, context->allocate_output(0, out_shape, &out));
// get the corresponding Eigen tensors for data access
auto handle_tensor = handle.flat<string>().data();
auto val_tensor = val.flat<double>().data();
auto out_tensor = out->flat<string>().data();
// implement your forward function here
// context->tensors_[string(*handle_tensor)] = val;
ds.vdata[string(*handle_tensor)] = std::vector<double>(val_tensor, val_tensor+10);
*out_tensor = *handle_tensor;
printf("Adding %s to collections.\n", string(*handle_tensor).c_str());
printf("\n========Existing Keys========\n");
for(auto & kv: ds.vdata){
printf("Key %s\n", kv.first.c_str());
}
}
};
REGISTER_KERNEL_BUILDER(Name("SaveTensor").Device(DEVICE_CPU), SaveTensorOp);GetTensor.cpp
#include "Saver.h"
#include "tensorflow/core/framework/op_kernel.h"
#include "tensorflow/core/framework/tensor_shape.h"
#include "tensorflow/core/platform/default/logging.h"
#include "tensorflow/core/framework/shape_inference.h"
#include<cmath>
#include<string>
#include<map>
#include<eigen3/Eigen/Core>
using std::string;
using namespace tensorflow;
REGISTER_OP("GetTensor")
.Input("handle : string")
.Output("val : double")
.SetShapeFn([](::tensorflow::shape_inference::InferenceContext* c) {
shape_inference::ShapeHandle handle_shape;
TF_RETURN_IF_ERROR(c->WithRank(c->input(0), 0, &handle_shape));
c->set_output(0, c->Vector(-1));
return Status::OK();
});
class GetTensorOp : public OpKernel {
private:
public:
explicit GetTensorOp(OpKernelConstruction* context) : OpKernel(context) {
}
void Compute(OpKernelContext* context) override {
DCHECK_EQ(1, context->num_inputs());
const Tensor& handle = context->input(0);
auto handle_tensor = handle.flat<string>().data();
auto val_shape = TensorShape({10});
Tensor *val = nullptr;
OP_REQUIRES_OK(context, context->allocate_output(0, val_shape, &val));
if (!ds.vdata.count(string(*handle_tensor))){
printf("[Get] Key %s does not exist.\n", string(*handle_tensor).c_str());
}
else{
printf("[Get] Key %s exists.\n", string(*handle_tensor).c_str());
auto v = ds.vdata[string(*handle_tensor)];
for(int i=0;i<10;i++){
val->flat<double>().data()[i] = v[i];
}
}
printf("\n========Existing Keys========\n");
for(auto & kv: ds.vdata){
printf("Key %s\n", kv.first.c_str());
}
}
};
REGISTER_KERNEL_BUILDER(Name("GetTensor").Device(DEVICE_CPU), GetTensorOp);DeleteTensor.cpp
#include "Saver.h"
#include "tensorflow/core/framework/op_kernel.h"
#include "tensorflow/core/framework/tensor_shape.h"
#include "tensorflow/core/platform/default/logging.h"
#include "tensorflow/core/framework/shape_inference.h"
#include<cmath>
#include<string>
#include<map>
#include<eigen3/Eigen/Core>
using std::string;
using namespace tensorflow;
REGISTER_OP("DeleteTensor")
.Input("handle : string")
.Output("val : bool")
.SetShapeFn([](::tensorflow::shape_inference::InferenceContext* c) {
shape_inference::ShapeHandle handle_shape;
TF_RETURN_IF_ERROR(c->WithRank(c->input(0), 0, &handle_shape));
c->set_output(0, c->Scalar());
return Status::OK();
});
class DeleteTensorOp : public OpKernel {
private:
public:
explicit DeleteTensorOp(OpKernelConstruction* context) : OpKernel(context) {
}
void Compute(OpKernelContext* context) override {
DCHECK_EQ(1, context->num_inputs());
const Tensor& handle = context->input(0);
auto handle_tensor = handle.flat<string>().data();
auto val_shape = TensorShape({});
Tensor *val = nullptr;
OP_REQUIRES_OK(context, context->allocate_output(0, val_shape, &val));
if (ds.vdata.count(string(*handle_tensor))){
ds.vdata.erase(string(*handle_tensor));
printf("[Delete] Erase key %s.\n", string(*handle_tensor).c_str());
*(val->flat<bool>().data()) = true;
}
else{
printf("[Delete] Key %s does not exist.\n", string(*handle_tensor).c_str());
*(val->flat<bool>().data()) = false;
}
printf("\n========Existing Keys========\n");
for(auto & kv: ds.vdata){
printf("Key %s\n", kv.first.c_str());
}
}
};
REGISTER_KERNEL_BUILDER(Name("DeleteTensor").Device(DEVICE_CPU), DeleteTensorOp);Here is part of the CMakeLists.txt used for compilation, where we link XXTensor.cpp with Saver
add_library(Saver SHARED Saver.cpp)
set_property(TARGET Saver PROPERTY POSITION_INDEPENDENT_CODE ON)
add_library(SaveTensor SHARED SaveTensor.cpp)
set_property(TARGET SaveTensor PROPERTY POSITION_INDEPENDENT_CODE ON)
target_link_libraries(SaveTensor ${TF_LIB_FILE} Saver)
add_library(GetTensor SHARED GetTensor.cpp)
set_property(TARGET GetTensor PROPERTY POSITION_INDEPENDENT_CODE ON)
target_link_libraries(GetTensor ${TF_LIB_FILE} Saver)
add_library(DeleteTensor SHARED DeleteTensor.cpp)
set_property(TARGET DeleteTensor PROPERTY POSITION_INDEPENDENT_CODE ON)
target_link_libraries(DeleteTensor ${TF_LIB_FILE} Saver)We can test our implementation with
using ADCME
save_tensor = load_op_and_grad("./build/libSaveTensor","save_tensor")
get_tensor = load_op_and_grad("./build/libGetTensor","get_tensor")
delete_tensor = load_op_and_grad("./build/libDeleteTensor","delete_tensor")
val = constant(rand(10))
t1 = tf.constant("tensor1")
t2 = tf.constant("tensor2")
t3 = tf.constant("tensor3")
u1 = save_tensor(t1,val)
u2 = save_tensor(t2,2*val)
u3 = save_tensor(t3,3*val)
z1 = get_tensor(t1);
z2 = get_tensor(t2);
z3 = get_tensor(t3);
d1 = delete_tensor(t1);
d2 = delete_tensor(t2);
d3 = delete_tensor(t3);
sess = Session();
run(sess, [u1,u2,u3])
run(sess, z1)
run(sess, z2)
run(sess, z3)
run(sess, d2)The expected output is
Adding tensor3 to collections.
========Existing Keys========
Key tensor1
Key tensor3
Adding tensor2 to collections.
========Existing Keys========
Key tensor1
Key tensor2
Key tensor3
Adding tensor1 to collections.
========Existing Keys========
Key tensor1
Key tensor2
Key tensor3
[Get] Key tensor1 exists.
========Existing Keys========
Key tensor1
Key tensor2
Key tensor3
[Get] Key tensor2 exists.
========Existing Keys========
Key tensor1
Key tensor2
Key tensor3
[Get] Key tensor3 exists.
========Existing Keys========
Key tensor1
Key tensor2
Key tensor3
[Delete] Erase key tensor2.
========Existing Keys========
Key tensor1
Key tensor3For example, in this article we use the technique introduced here to design a custom operator for direct methods for sparse matrix solutions.