Controlling Stochastic Differential Equations
In this tutorial, we show how to use DiffEqFlux to control the time evolution of a system described by a stochastic differential equations (SDE). Specifically, we consider a continuously monitored qubit described by an SDE in the Ito sense with multiplicative scalar noise (see [1] for a reference):
\[dψ = b(ψ(t), Ω(t))ψ(t) dt + σ(ψ(t))ψ(t) dW_t .\]
We use a predictive model to map the quantum state of the qubit, ψ(t), at each time to the control parameter Ω(t) which rotates the quantum state about the x-axis of the Bloch sphere to ultimately prepare and stabilize the qubit in the excited state.
Copy-Pasteable Code
Before getting to the explanation, here's some code to start with. We will follow a full explanation of the definition and training process:
# load packages
using DiffEqFlux
using StochasticDiffEq, DiffEqCallbacks, DiffEqNoiseProcess
using Statistics, LinearAlgebra, Random
using Plots
#################################################
lr = 0.01f0
epochs = 100
numtraj = 16 # number of trajectories in parallel simulations for training
numtrajplot = 32 # .. for plotting
# time range for the solver
dt = 0.0005f0
tinterval = 0.05f0
tstart = 0.0f0
Nintervals = 20 # total number of intervals, total time = t_interval*Nintervals
tspan = (tstart,tinterval*Nintervals)
ts = Array(tstart:dt:(Nintervals*tinterval+dt)) # time array for noise grid
# Hamiltonian parameters
Δ = 20.0f0
Ωmax = 10.0f0 # control parameter (maximum amplitude)
κ = 0.3f0
# loss hyperparameters
C1 = Float32(1.0) # evolution state fidelity
struct Parameters{flType,intType,tType}
lr::flType
epochs::intType
numtraj::intType
numtrajplot::intType
dt::flType
tinterval::flType
tspan::tType
Nintervals::intType
ts::Vector{flType}
Δ::flType
Ωmax::flType
κ::flType
C1::flType
end
myparameters = Parameters{typeof(dt),typeof(numtraj), typeof(tspan)}(
lr, epochs, numtraj, numtrajplot, dt, tinterval, tspan, Nintervals, ts,
Δ, Ωmax, κ, C1)
################################################
# Define Neural Network
# state-aware
nn = FastChain(
FastDense(4, 32, relu),
FastDense(32, 1, tanh))
p_nn = initial_params(nn) # random initial parameters
###############################################
# initial state anywhere on the Bloch sphere
function prepare_initial(dt, n_par)
# shape 4 x n_par
# input number of parallel realizations and dt for type inference
# random position on the Bloch sphere
theta = acos.(2*rand(typeof(dt),n_par).-1) # uniform sampling for cos(theta) between -1 and 1
phi = rand(typeof(dt),n_par)*2*pi # uniform sampling for phi between 0 and 2pi
# real and imaginary parts ceR, cdR, ceI, cdI
u0 = [cos.(theta/2), sin.(theta/2).*cos.(phi), false*theta, sin.(theta/2).*sin.(phi)]
return vcat(transpose.(u0)...) # build matrix
end
# target state
# ψtar = |up>
u0 = prepare_initial(myparameters.dt, myparameters.numtraj)
###############################################
# Define SDE
function qubit_drift!(du,u,p,t)
# expansion coefficients |Ψ> = ce |e> + cd |d>
ceR, cdR, ceI, cdI = u # real and imaginary parts
# Δ: atomic frequency
# Ω: Rabi frequency for field in x direction
# κ: spontaneous emission
Δ, Ωmax, κ = p[end-2:end]
nn_weights = p[1:end-3]
Ω = (nn(u, nn_weights).*Ωmax)[1]
@inbounds begin
du[1] = 1//2*(ceI*Δ-ceR*κ+cdI*Ω)
du[2] = -cdI*Δ/2 + 1*ceR*(cdI*ceI+cdR*ceR)*κ+ceI*Ω/2
du[3] = 1//2*(-ceR*Δ-ceI*κ-cdR*Ω)
du[4] = cdR*Δ/2 + 1*ceI*(cdI*ceI+cdR*ceR)*κ-ceR*Ω/2
end
return nothing
end
function qubit_diffusion!(du,u,p,t)
ceR, cdR, ceI, cdI = u # real and imaginary parts
κ = p[end]
du .= false
@inbounds begin
#du[1] = zero(ceR)
du[2] += sqrt(κ)*ceR
#du[3] = zero(ceR)
du[4] += sqrt(κ)*ceI
end
return nothing
end
# normalization callback
condition(u,t,integrator) = true
function affect!(integrator)
integrator.u=integrator.u/norm(integrator.u)
end
callback = DiscreteCallback(condition,affect!,save_positions=(false,false))
CreateGrid(t,W1) = NoiseGrid(t,W1)
Zygote.@nograd CreateGrid #avoid taking grads of this function
# set scalar random process
W = sqrt(myparameters.dt)*randn(typeof(myparameters.dt),size(myparameters.ts)) #for 1 trajectory
W1 = cumsum([zero(myparameters.dt); W[1:end-1]], dims=1)
NG = CreateGrid(myparameters.ts,W1)
# get control pulses
p_all = [p_nn; myparameters.Δ; myparameters.Ωmax; myparameters.κ]
# define SDE problem
prob = SDEProblem{true}(qubit_drift!, qubit_diffusion!, vec(u0[:,1]), myparameters.tspan, p_all,
callback=callback, noise=NG
)
#########################################
# compute loss
function g(u,p,t)
ceR = @view u[1,:,:]
cdR = @view u[2,:,:]
ceI = @view u[3,:,:]
cdI = @view u[4,:,:]
p[1]*mean((cdR.^2 + cdI.^2) ./ (ceR.^2 + cdR.^2 + ceI.^2 + cdI.^2))
end
function loss(p, u0, prob::SDEProblem, myparameters::Parameters;
alg=EM(), sensealg = BacksolveAdjoint()
)
pars = [p; myparameters.Δ; myparameters.Ωmax; myparameters.κ]
function prob_func(prob, i, repeat)
# prepare initial state and applied control pulse
u0tmp = deepcopy(vec(u0[:,i]))
W = sqrt(myparameters.dt)*randn(typeof(myparameters.dt),size(myparameters.ts)) #for 1 trajectory
W1 = cumsum([zero(myparameters.dt); W[1:end-1]], dims=1)
NG = CreateGrid(myparameters.ts,W1)
remake(prob,
p = pars,
u0 = u0tmp,
callback = callback,
noise=NG)
end
ensembleprob = EnsembleProblem(prob,
prob_func = prob_func,
safetycopy = true
)
_sol = solve(ensembleprob, alg, EnsembleThreads(),
sensealg=sensealg,
saveat=myparameters.tinterval,
dt=myparameters.dt,
adaptive=false,
trajectories=myparameters.numtraj, batch_size=myparameters.numtraj)
A = convert(Array,_sol)
loss = g(A,[myparameters.C1],nothing)
return loss
end
#########################################
# visualization -- run for new batch
function visualize(p, u0, prob::SDEProblem, myparameters::Parameters;
alg=EM(),
)
pars = [p; myparameters.Δ; myparameters.Ωmax; myparameters.κ]
function prob_func(prob, i, repeat)
# prepare initial state and applied control pulse
u0tmp = deepcopy(vec(u0[:,i]))
W = sqrt(myparameters.dt)*randn(typeof(myparameters.dt),size(myparameters.ts)) #for 1 trajectory
W1 = cumsum([zero(myparameters.dt); W[1:end-1]], dims=1)
NG = CreateGrid(myparameters.ts,W1)
remake(prob,
p = pars,
u0 = u0tmp,
callback = callback,
noise=NG)
end
ensembleprob = EnsembleProblem(prob,
prob_func = prob_func,
safetycopy = true
)
u = solve(ensembleprob, alg, EnsembleThreads(),
saveat=myparameters.tinterval,
dt=myparameters.dt,
adaptive=false, #abstol=1e-6, reltol=1e-6,
trajectories=myparameters.numtrajplot, batch_size=myparameters.numtrajplot)
ceR = @view u[1,:,:]
cdR = @view u[2,:,:]
ceI = @view u[3,:,:]
cdI = @view u[4,:,:]
infidelity = @. (cdR^2 + cdI^2) / (ceR^2 + cdR^2 + ceI^2 + cdI^2)
meaninfidelity = mean(infidelity)
loss = myparameters.C1*meaninfidelity
@info "Loss: " loss
fidelity = @. (ceR^2 + ceI^2) / (ceR^2 + cdR^2 + ceI^2 + cdI^2)
mf = mean(fidelity, dims=2)[:]
sf = std(fidelity, dims=2)[:]
pl1 = plot(0:myparameters.Nintervals, mf,
ribbon = sf,
ylim = (0,1), xlim = (0,myparameters.Nintervals),
c=1, lw = 1.5, xlabel = "steps i", ylabel="Fidelity", legend=false)
pl = plot(pl1, legend = false, size=(400,360))
return pl, loss
end
###################################
# training loop
@info "Start Training.."
# optimize the parameters for a few epochs with ADAM on time span Nint
opt = ADAM(myparameters.lr)
list_plots = []
losses = []
for epoch in 1:myparameters.epochs
println("epoch: $epoch / $(myparameters.epochs)")
local u0 = prepare_initial(myparameters.dt, myparameters.numtraj)
_dy, back = @time Zygote.pullback(p -> loss(p, u0, prob, myparameters,
sensealg=BacksolveAdjoint()
), p_nn)
@show _dy
gs = @time back(one(_dy))[1]
# store loss
push!(losses, _dy)
if (epoch % myparameters.epochs == 0) || (epoch == 1)
# plot/store every xth epoch
@info "plotting.."
local u0 = prepare_initial(myparameters.dt, myparameters.numtrajplot)
pl, test_loss = visualize(p_nn, u0, prob, myparameters)
println("Loss (epoch: $epoch): $test_loss")
display(pl)
push!(list_plots, pl)
end
Flux.Optimise.update!(opt, p_nn, gs)
println("")
end
# plot training loss
pl = plot(losses, lw = 1.5, xlabel = "some epochs", ylabel="Loss", legend=false)
savefig(display(list_plots[end], "fidelity.png")Output:
[ Info: Start Training..
epoch: 1 / 100
38.519219 seconds (85.38 M allocations: 4.316 GiB, 3.37% gc time)
_dy = 0.63193643f0
26.232970 seconds (122.33 M allocations: 5.899 GiB, 7.26% gc time)
...
[ Info: plotting..
┌ Info: Loss:
└ loss = 0.11777343f0
Loss (epoch: 100): 0.11777343Step-by-step description
Load packages
using DiffEqFlux
using StochasticDiffEq, DiffEqCallbacks, DiffEqNoiseProcess
using Statistics, LinearAlgebra, Random
using PlotsParameters
We define the parameters of the qubit and hyper-parameters of the training process.
lr = 0.01f0
epochs = 100
numtraj = 16 # number of trajectories in parallel simulations for training
numtrajplot = 32 # .. for plotting
# time range for the solver
dt = 0.0005f0
tinterval = 0.05f0
tstart = 0.0f0
Nintervals = 20 # total number of intervals, total time = t_interval*Nintervals
tspan = (tstart,tinterval*Nintervals)
ts = Array(tstart:dt:(Nintervals*tinterval+dt)) # time array for noise grid
# Hamiltonian parameters
Δ = 20.0f0
Ωmax = 10.0f0 # control parameter (maximum amplitude)
κ = 0.3f0
# loss hyperparameters
C1 = Float32(1.0) # evolution state fidelity
struct Parameters{flType,intType,tType}
lr::flType
epochs::intType
numtraj::intType
numtrajplot::intType
dt::flType
tinterval::flType
tspan::tType
Nintervals::intType
ts::Vector{flType}
Δ::flType
Ωmax::flType
κ::flType
C1::flType
end
myparameters = Parameters{typeof(dt),typeof(numtraj), typeof(tspan)}(
lr, epochs, numtraj, numtrajplot, dt, tinterval, tspan, Nintervals, ts,
Δ, Ωmax, κ, C1)In plain terms, the quantities that were defined are:
lr= learning rate of the optimizerepochs= number of epochs in the training processnumtraj= number of simulated trajectories in the training processnumtrajplot= number of simulated trajectories to visualize the performancedt= time step for solver (initialdtif adaptive)tinterval= time spacing between checkpointstspan= time spanNintervals= number of checkpointsts= discretization of the entire time interval, used forNoiseGridΔ= detuning between the qubit and the laserΩmax= maximum frequency of the control laserκ= decay rateC1= loss function hyper-parameter
Controller
We use a neural network to control the parameter Ω(t). Alternatively, one could also, e.g., use tensor layers.
# state-aware
nn = FastChain(
FastDense(4, 32, relu),
FastDense(32, 1, tanh))
p_nn = initial_params(nn) # random initial parametersInitial state
We prepare n_par initial states, uniformly distributed over the Bloch sphere. To avoid complex numbers in our simulations, we split the state of the qubit
\[ ψ(t) = c_e(t) (1,0) + c_d(t) (0,1)\]
into its real and imaginary part.
# initial state anywhere on the Bloch sphere
function prepare_initial(dt, n_par)
# shape 4 x n_par
# input number of parallel realizations and dt for type inference
# random position on the Bloch sphere
theta = acos.(2*rand(typeof(dt),n_par).-1) # uniform sampling for cos(theta) between -1 and 1
phi = rand(typeof(dt),n_par)*2*pi # uniform sampling for phi between 0 and 2pi
# real and imaginary parts ceR, cdR, ceI, cdI
u0 = [cos.(theta/2), sin.(theta/2).*cos.(phi), false*theta, sin.(theta/2).*sin.(phi)]
return vcat(transpose.(u0)...) # build matrix
end
# target state
# ψtar = |e>
u0 = prepare_initial(myparameters.dt, myparameters.numtraj)Defining the SDE
We define the drift and diffusion term of the qubit. The SDE doesn't preserve the norm of the quantum state. To ensure the normalization of the state, we add a DiscreteCallback after each time step. Further, we use a NoiseGrid from the DiffEqNoiseProcess package, as one possibility to simulate a 1D Brownian motion. Note that the NN is placed directly into the drift function, thus the control parameter Ω is continuously updated.
# Define SDE
function qubit_drift!(du,u,p,t)
# expansion coefficients |Ψ> = ce |e> + cd |d>
ceR, cdR, ceI, cdI = u # real and imaginary parts
# Δ: atomic frequency
# Ω: Rabi frequency for field in x direction
# κ: spontaneous emission
Δ, Ωmax, κ = p[end-2:end]
nn_weights = p[1:end-3]
Ω = (nn(u, nn_weights).*Ωmax)[1]
@inbounds begin
du[1] = 1//2*(ceI*Δ-ceR*κ+cdI*Ω)
du[2] = -cdI*Δ/2 + 1*ceR*(cdI*ceI+cdR*ceR)*κ+ceI*Ω/2
du[3] = 1//2*(-ceR*Δ-ceI*κ-cdR*Ω)
du[4] = cdR*Δ/2 + 1*ceI*(cdI*ceI+cdR*ceR)*κ-ceR*Ω/2
end
return nothing
end
function qubit_diffusion!(du,u,p,t)
ceR, cdR, ceI, cdI = u # real and imaginary parts
κ = p[end]
du .= false
@inbounds begin
#du[1] = zero(ceR)
du[2] += sqrt(κ)*ceR
#du[3] = zero(ceR)
du[4] += sqrt(κ)*ceI
end
return nothing
end
# normalization callback
condition(u,t,integrator) = true
function affect!(integrator)
integrator.u=integrator.u/norm(integrator.u)
end
callback = DiscreteCallback(condition,affect!,save_positions=(false,false))
CreateGrid(t,W1) = NoiseGrid(t,W1)
Zygote.@nograd CreateGrid #avoid taking grads of this function
# set scalar random process
W = sqrt(myparameters.dt)*randn(typeof(myparameters.dt),size(myparameters.ts)) #for 1 trajectory
W1 = cumsum([zero(myparameters.dt); W[1:end-1]], dims=1)
NG = CreateGrid(myparameters.ts,W1)
# get control pulses
p_all = [p_nn; myparameters.Δ; myparameters.Ωmax; myparameters.κ]
# define SDE problem
prob = SDEProblem{true}(qubit_drift!, qubit_diffusion!, vec(u0[:,1]), myparameters.tspan, p_all,
callback=callback, noise=NG
)Compute loss function
We'd like to prepare the excited state of the qubit. An appropriate choice for the loss function is the infidelity of the state ψ(t) with respect to the excited state. We create a parallelized EnsembleProblem, where the prob_func creates a new NoiseGrid for every trajectory and loops over the initial states. The number of parallel trajectories and the used batch size can be tuned by the kwargs trajectories=.. and batchsize=.. in the solve call. See also the parallel ensemble simulation docs for a description of the available ensemble algorithms. To optimize only the parameters of the neural network, we use pars = [p; myparameters.Δ; myparameters.Ωmax; myparameters.κ]
# compute loss
function g(u,p,t)
ceR = @view u[1,:,:]
cdR = @view u[2,:,:]
ceI = @view u[3,:,:]
cdI = @view u[4,:,:]
p[1]*mean((cdR.^2 + cdI.^2) ./ (ceR.^2 + cdR.^2 + ceI.^2 + cdI.^2))
end
function loss(p, u0, prob::SDEProblem, myparameters::Parameters;
alg=EM(), sensealg = BacksolveAdjoint()
)
pars = [p; myparameters.Δ; myparameters.Ωmax; myparameters.κ]
function prob_func(prob, i, repeat)
# prepare initial state and applied control pulse
u0tmp = deepcopy(vec(u0[:,i]))
W = sqrt(myparameters.dt)*randn(typeof(myparameters.dt),size(myparameters.ts)) #for 1 trajectory
W1 = cumsum([zero(myparameters.dt); W[1:end-1]], dims=1)
NG = CreateGrid(myparameters.ts,W1)
remake(prob,
p = pars,
u0 = u0tmp,
callback = callback,
noise=NG)
end
ensembleprob = EnsembleProblem(prob,
prob_func = prob_func,
safetycopy = true
)
_sol = solve(ensembleprob, alg, EnsembleThreads(),
sensealg=sensealg,
saveat=myparameters.tinterval,
dt=myparameters.dt,
adaptive=false,
trajectories=myparameters.numtraj, batch_size=myparameters.numtraj)
A = convert(Array,_sol)
loss = g(A,[myparameters.C1],nothing)
return loss
endVisualization
To visualize the performance of the controller, we plot the mean value and standard deviation of the fidelity of a bunch of trajectories (myparameters.numtrajplot) as a function of the time steps at which loss values are computed.
function visualize(p, u0, prob::SDEProblem, myparameters::Parameters;
alg=EM(),
)
pars = [p; myparameters.Δ; myparameters.Ωmax; myparameters.κ]
function prob_func(prob, i, repeat)
# prepare initial state and applied control pulse
u0tmp = deepcopy(vec(u0[:,i]))
W = sqrt(myparameters.dt)*randn(typeof(myparameters.dt),size(myparameters.ts)) #for 1 trajectory
W1 = cumsum([zero(myparameters.dt); W[1:end-1]], dims=1)
NG = CreateGrid(myparameters.ts,W1)
remake(prob,
p = pars,
u0 = u0tmp,
callback = callback,
noise=NG)
end
ensembleprob = EnsembleProblem(prob,
prob_func = prob_func,
safetycopy = true
)
u = solve(ensembleprob, alg, EnsembleThreads(),
saveat=myparameters.tinterval,
dt=myparameters.dt,
adaptive=false, #abstol=1e-6, reltol=1e-6,
trajectories=myparameters.numtrajplot, batch_size=myparameters.numtrajplot)
ceR = @view u[1,:,:]
cdR = @view u[2,:,:]
ceI = @view u[3,:,:]
cdI = @view u[4,:,:]
infidelity = @. (cdR^2 + cdI^2) / (ceR^2 + cdR^2 + ceI^2 + cdI^2)
meaninfidelity = mean(infidelity)
loss = myparameters.C1*meaninfidelity
@info "Loss: " loss
fidelity = @. (ceR^2 + ceI^2) / (ceR^2 + cdR^2 + ceI^2 + cdI^2)
mf = mean(fidelity, dims=2)[:]
sf = std(fidelity, dims=2)[:]
pl1 = plot(0:myparameters.Nintervals, mf,
ribbon = sf,
ylim = (0,1), xlim = (0,myparameters.Nintervals),
c=1, lw = 1.5, xlabel = "steps i", ylabel="Fidelity", legend=false)
pl = plot(pl1, legend = false, size=(400,360))
return pl, loss
endTraining
We use the ADAM optimizer to optimize the parameters of the neural network. In each epoch, we draw new initial quantum states, compute the forward evolution, and, subsequently, the gradients of the loss function with respect to the parameters of the neural network. sensealg allows one to switch between the different sensitivity modes. InterpolatingAdjoint and BacksolveAdjoint are the two possible continuous adjoint sensitivity methods. The necessary correction between Ito and Stratonovich integrals is computed under the hood in the DiffEqSensitivity package.
# optimize the parameters for a few epochs with ADAM on time span Nint
opt = ADAM(myparameters.lr)
list_plots = []
losses = []
for epoch in 1:myparameters.epochs
println("epoch: $epoch / $(myparameters.epochs)")
local u0 = prepare_initial(myparameters.dt, myparameters.numtraj)
_dy, back = @time Zygote.pullback(p -> loss(p, u0, prob, myparameters,
sensealg=BacksolveAdjoint()
), p_nn)
@show _dy
gs = @time back(one(_dy))[1]
# store loss
push!(losses, _dy)
if (epoch % myparameters.epochs == 0) || (epoch == 1)
# plot/store every xth epoch
@info "plotting.."
local u0 = prepare_initial(myparameters.dt, myparameters.numtrajplot)
pl, test_loss = visualize(p_nn, u0, prob, myparameters)
println("Loss (epoch: $epoch): $test_loss")
display(pl)
push!(list_plots, pl)
end
Flux.Optimise.update!(opt, p_nn, gs)
println("")
end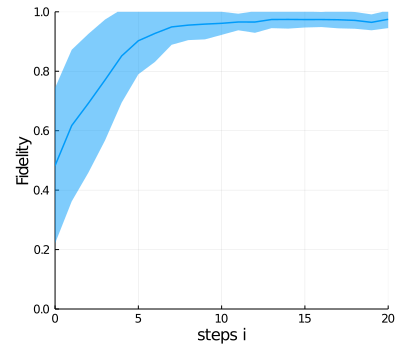
References
[1] Schäfer, Frank, Pavel Sekatski, Martin Koppenhöfer, Christoph Bruder, and Michal Kloc. "Control of stochastic quantum dynamics by differentiable programming." Machine Learning: Science and Technology 2, no. 3 (2021): 035004.